
참고
머신러닝의 개념
일반적인 프로그램은 개발자가 프로그램의 동작 방식을 직접 설계하는 방식이다. 하지만 자율주행 자동차라던지 프로그램에서 발생하는 변수들의 수가 셀 수 없이 많을 때는 개발자가 일일이 조건문으로 설계를 한다는 것은 거의 불가능에 가깝다. 이를 위해 프로그램이 스스로 학습하여 문제를 해결하는 방법이 머신러닝이다.
머신러닝의 학습 방법
1) 지도 학습 - 학습 데이터를 이용

학습데이터란 입력과 정답으로 된 데이터 셋을 가지고 학습하는 방법이다. 수많은 데이터 셋을 학습을 하고 나서 입력이 주어 질 때, 그 입력이 꿀벌일 확률 5% , 고양이일 확률 80%, 강아지일 확률 10% 각각 나오며 가장 높은 확률을 값으로 예측한다.
ex) 선형 회귀 - Linear Regression
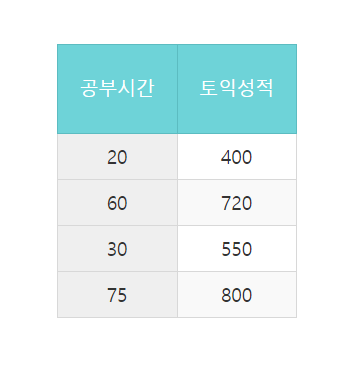

선형 회귀는 입력과 정답이 비례 관계에 있을 때 학습을 하는 방법이다. 위 예제는 공부시간이 많으면 토익점수가 높고 공부시간이 적으면 토익점수가 낮으므로 비례관계라고 볼 수 있다. 우리는 학습 데이터를 1차함수 모델로 가정 할 수 있고 학습을 진행한다.
실제 1차 함수의 수식은 기울기가 a고 상수가 b인 y = ax +b 이다. 하지만 머신러닝에서는 H(x) = wx + b로 정의한다. w는 가중치이다.
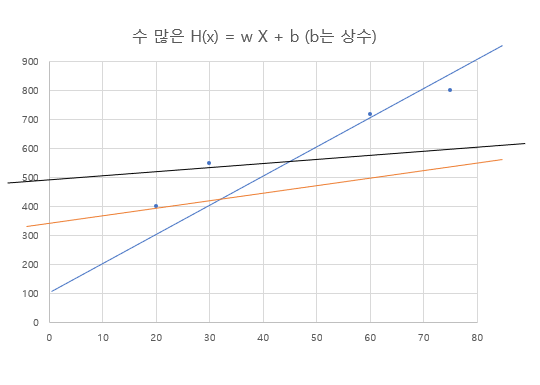
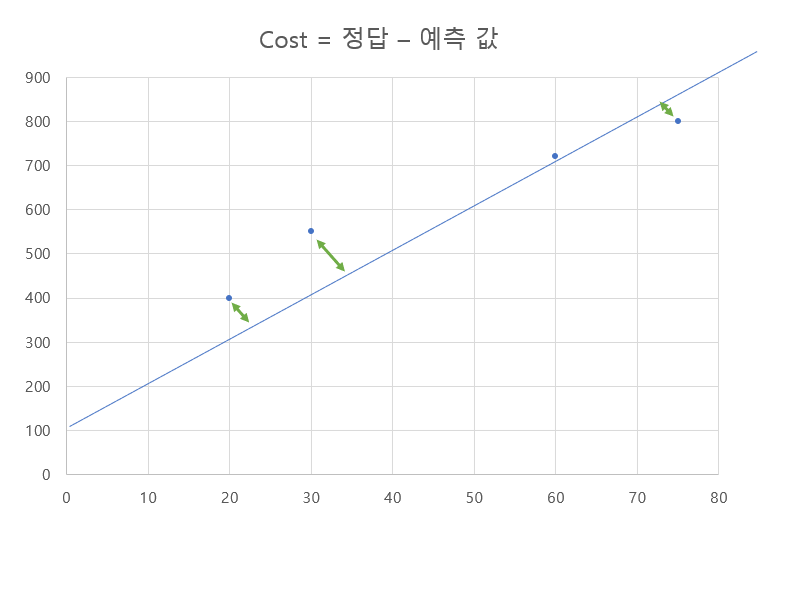
가중치인 W의 값에 따라 수많은 H(x)가 생길 수 있다. 임시로 W값을 설정하고 학습을 시작하면 각 데이터의 입력에 대한 예측 값과 실제 정답값의 차이를 의미하는 Cost의 값이 생성되고 이 모든 Cost 값을 더한 것이 W의 총 Cost가 된다. 쉽게 정리하자면 W마다 총 Cost의 값을 비교하여 가장 Cost가 낮은 W를 찾는 과정이다.
2) 비 지도 학습
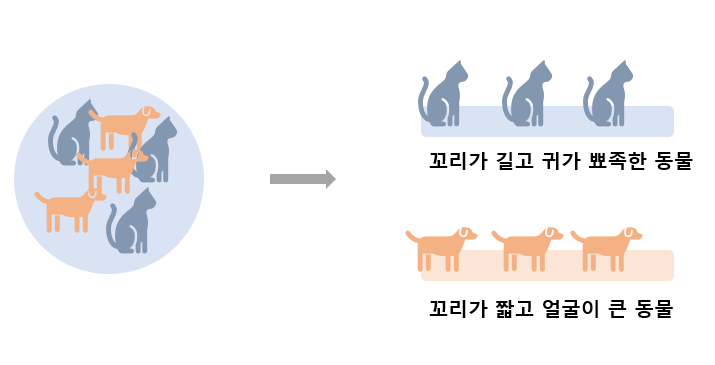
비 지도 학습의 학습 데이터는 오직 입력만 주어지기 때문에 기계가 스스로 입력에 대해 특성을 분류하는 방법이다.
꼬리가 긴 고양이들을 한 분류로 묶고,
얼굴이 큰 강아지들을 한 분류로 묶는 등 스스로 입력 데이터의 특성에 맞게 분류를 하여 군집화를 한다.
3) 강화 학습
학습을 하는 에이전트와 학습의 환경 속에서 에이전트의 행동에 따라 주어지는 상을 최대화하고 벌을 최소화하는 학습 방법이다.
유명한 알파고도 이 방식으로 설계되었다고 한다.
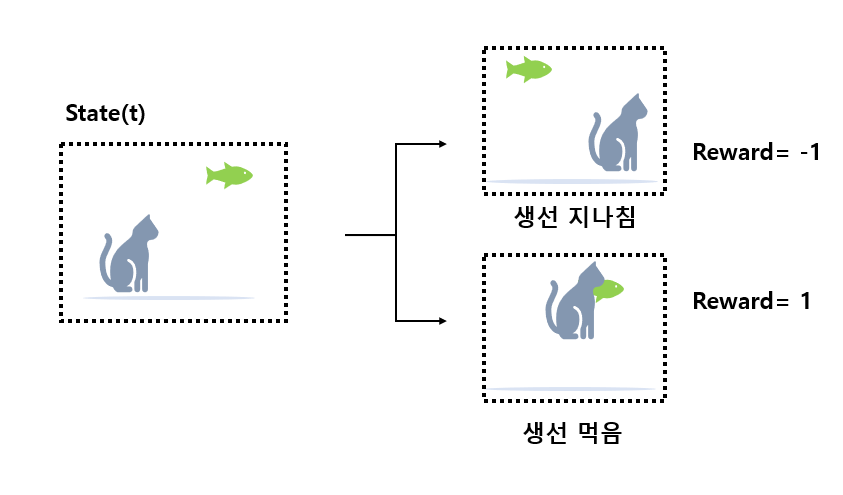
에이전트인 고양이는 생선을 먹으면 기분좋다는 환경에 있다고 했을 때, 시간별로 발생하는 State가 입력으로 들어온다.
처음에는 랜덤 값으로 그냥 지나치거나 먹게되고 이때에 따른 보상을 받게 되면서 기계는 점점 보상을 크게 얻는 쪽으로 학습을 진행하게 된다.
'ML' 카테고리의 다른 글
| [ML]텍스트 마이닝와 자연어 처리 - 어떤 API가 있을 까? (0) | 2020.05.03 |
|---|
참고
머신러닝의 개념
일반적인 프로그램은 개발자가 프로그램의 동작 방식을 직접 설계하는 방식이다. 하지만 자율주행 자동차라던지 프로그램에서 발생하는 변수들의 수가 셀 수 없이 많을 때는 개발자가 일일이 조건문으로 설계를 한다는 것은 거의 불가능에 가깝다. 이를 위해 프로그램이 스스로 학습하여 문제를 해결하는 방법이 머신러닝이다.
머신러닝의 학습 방법
1) 지도 학습 - 학습 데이터를 이용
학습데이터란 입력과 정답으로 된 데이터 셋을 가지고 학습하는 방법이다. 수많은 데이터 셋을 학습을 하고 나서 입력이 주어 질 때, 그 입력이 꿀벌일 확률 5% , 고양이일 확률 80%, 강아지일 확률 10% 각각 나오며 가장 높은 확률을 값으로 예측한다.
ex) 선형 회귀 - Linear Regression
선형 회귀는 입력과 정답이 비례 관계에 있을 때 학습을 하는 방법이다. 위 예제는 공부시간이 많으면 토익점수가 높고 공부시간이 적으면 토익점수가 낮으므로 비례관계라고 볼 수 있다. 우리는 학습 데이터를 1차함수 모델로 가정 할 수 있고 학습을 진행한다.
실제 1차 함수의 수식은 기울기가 a고 상수가 b인 y = ax +b 이다. 하지만 머신러닝에서는 H(x) = wx + b로 정의한다. w는 가중치이다.
가중치인 W의 값에 따라 수많은 H(x)가 생길 수 있다. 임시로 W값을 설정하고 학습을 시작하면 각 데이터의 입력에 대한 예측 값과 실제 정답값의 차이를 의미하는 Cost의 값이 생성되고 이 모든 Cost 값을 더한 것이 W의 총 Cost가 된다. 쉽게 정리하자면 W마다 총 Cost의 값을 비교하여 가장 Cost가 낮은 W를 찾는 과정이다.
2) 비 지도 학습
비 지도 학습의 학습 데이터는 오직 입력만 주어지기 때문에 기계가 스스로 입력에 대해 특성을 분류하는 방법이다.
꼬리가 긴 고양이들을 한 분류로 묶고,
얼굴이 큰 강아지들을 한 분류로 묶는 등 스스로 입력 데이터의 특성에 맞게 분류를 하여 군집화를 한다.
3) 강화 학습
학습을 하는 에이전트와 학습의 환경 속에서 에이전트의 행동에 따라 주어지는 상을 최대화하고 벌을 최소화하는 학습 방법이다.
유명한 알파고도 이 방식으로 설계되었다고 한다.
에이전트인 고양이는 생선을 먹으면 기분좋다는 환경에 있다고 했을 때, 시간별로 발생하는 State가 입력으로 들어온다.
처음에는 랜덤 값으로 그냥 지나치거나 먹게되고 이때에 따른 보상을 받게 되면서 기계는 점점 보상을 크게 얻는 쪽으로 학습을 진행하게 된다.
'ML' 카테고리의 다른 글
| [ML]텍스트 마이닝와 자연어 처리 - 어떤 API가 있을 까? (0) | 2020.05.03 |
|---|